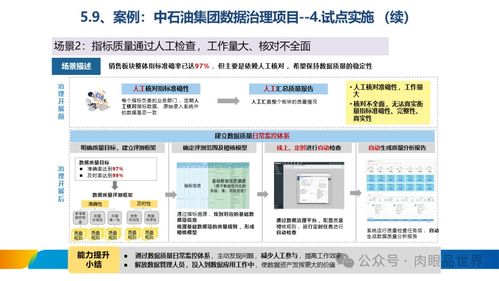
构建混合云无服务器数据仓库 基于Amazon EMR Serverless、Athena、DolphinScheduler与本地TiDB、HDFS的集成实践

在当今数据驱动的时代,企业面临着数据处理敏捷性、成本效率与混合云架构兼容性的多重挑战。传统数据仓库与数据处理流程往往依赖于固定的基础设施,难以灵活应对波动的计算需求。本文将探讨如何利用Amazon EMR Serverless、Amazon Athena、Apache DolphinScheduler,结合本地的TiDB数据库与HDFS分布式文件系统,构建一个高效、弹性且成本优化的无服务器数据仓库与数据处理服务。
一、 架构概览与核心组件角色
本方案的核心思想是构建一个“混合部署、无服务器优先”的数据平台,将云端强大的弹性计算与存储能力,同本地数据源与特定服务相结合。
- 数据存储层:
- 本地HDFS:作为原始数据、半结构化/非结构化数据的初始着陆区或归档层,尤其适用于对数据本地化有严格要求或网络传输成本敏感的场景。
- 本地TiDB:作为需要强一致事务支持、低延迟查询的在线业务数据库(OLTP),同时其与MySQL协议兼容的特性,也使其成为数据集成的重要一环。
- Amazon S3:作为云端数据湖的核心存储,通过连接器(如HDFS S3A Connector)或数据同步工具,可将HDFS数据高效同步至S3,为上层无服务器计算提供数据基础。
- 无服务器计算与查询层:
- Amazon EMR Serverless:这是数据处理的核心引擎。它允许用户直接提交Spark、Hive等作业,而无需预置或管理集群。当需要运行ETL/ELT作业、复杂的数据转换或机器学习任务时,可瞬间启动任务,按实际计算资源消耗付费,任务完成后资源自动释放,完美应对间歇性、不定时的数据处理需求。
- Amazon Athena:作为无服务器的交互式查询服务,可直接使用标准SQL分析S3中的数据。它非常适合进行即席查询、数据探查和生成报表。Athena的联邦查询功能甚至可以扩展至查询本地TiDB等数据源(需通过Lambda连接器),实现跨云本地的统一SQL查询界面。
- 统一调度与编排层:
- Apache DolphinScheduler:作为开源的分布式可视化工作流任务调度平台,它是整个数据流水线的“中枢神经”。我们可以将其部署在本地或云端虚拟机,用于编排复杂的混合任务依赖关系,例如:
- 定时触发HDFS到S3的数据同步任务。
- 编排EMR Serverless作业,处理S3中的数据并写回。
- 调度对TiDB的数据抽取任务,并将结果写入S3。
- 触发Athena查询任务,生成聚合表或业务报表。
- 监控所有任务的执行状态与告警。
二、 关键集成与数据处理流程
一个典型的数据处理流程可能如下所示:
- 数据摄入与湖仓同步:
- 业务数据持续写入本地TiDB,日志类数据写入本地HDFS。
- DolphinScheduler调度数据同步任务(可使用Spark作业、Sqoop或定制脚本),定期将TiDB的增量数据、HDFS的新增文件同步至Amazon S3的数据湖中。
- 云端无服务器ETL处理:
- DolphinScheduler调用AWS SDK或API,提交一个EMR Serverless Spark作业。该作业读取S3中的原始数据,进行清洗、转换、聚合等操作,并将处理后的结构化数据以Parquet/ORC等列式格式写回S3的特定路径,形成“数据湖仓”的轻度汇总层或主题域层。
- 交互式查询与分析:
- 数据分析师或业务系统通过Amazon Athena,直接使用SQL对S3中处理后的数据执行快速的即席查询,生成业务洞察。
- 对于需要结合TiDB最新交易数据的查询,可探索使用Athena Federated Query,通过预置的Lambda连接器将查询下推至本地TiDB,在Athena中实现跨数据源的关联分析。
- 结果反馈与数据应用:
- ETL处理后的聚合数据,可以再次由DolphinScheduler调度,回写至本地TiDB(作为维度表或汇果),供低延迟的在线应用查询。
- 也可将Athena的查询结果直接对接可视化工具(如Amazon QuickSight、Tableau),形成固定报表或动态看板。
三、 核心优势与价值
- 极致的成本优化:EMR Serverless和Athena均按扫描/计算的数据量付费,无闲置集群成本。配合S3的低成本存储,实现了“用多少,付多少”的理想模型。
- 卓越的弹性与敏捷性:无需容量规划,计算能力可瞬间从零扩展至PB级处理需求,轻松应对业务高峰与数据量增长。
- 混合架构的灵活性:既利用了云端无服务的先进能力,又保留了本地关键数据源与存储,满足数据合规、延迟和既有投资保护的要求。
- 运维简化:无需管理Hadoop/Spark集群的运维、扩缩容、打补丁等复杂工作,团队可更专注于数据逻辑与业务价值。
- 统一的调度管控:通过DolphinScheduler将云上与本地任务可视化编排,保障了端到端数据 pipeline 的可靠性、可监控性与可维护性。
四、 实施考量与挑战
- 网络与安全:需确保本地数据中心与AWS之间稳定、安全的网络连接(如DX/VPN),并精细配置VPC、安全组、IAM角色与本地防火墙策略,以保障数据传输与API调用的安全。
- 数据同步延迟:需根据业务对数据新鲜度的要求,合理设计从TiDB/HDFS到S3的同步频率与策略(全量/增量)。
- 元数据与权限统一:建议使用AWS Glue Data Catalog作为S3数据的中央元数据存储,并与Athena、EMR Serverless无缝集成。权限管理需统筹考虑IAM、本地数据库账号及HDFS权限。
- 本地调度器高可用:为确保DolphinScheduler自身的高可用性,建议采用其主从或多活部署模式。
###
通过整合Amazon EMR Serverless与Athena提供的无服务器计算能力,Apache DolphinScheduler的强健编排能力,以及本地TiDB与HDFS的存储与事务能力,企业可以构建一个高度弹性、成本可控且适应混合云环境的现代数据仓库与处理服务。这种架构不仅降低了技术复杂度与运维负担,更赋予了数据团队快速响应业务变化、探索数据价值的强大能力,是传统数据架构向云原生、智能化演进的重要路径。
如若转载,请注明出处:http://www.591guke.com/product/42.html
更新时间:2026-02-27 06:09:28